Schedule 总结2
Taint & Toleration
podAffinity是一类属性,使节点拥有吸引某一类 Pod 的能力,Taint 则相反,使节点能够排斥一类特定的 Pod,Toleration 则允许调度器将 Pod 调度到带有 Taint 的节点上。
Taint 与 Toleration 相互配合,可以有效避免将一类 Pod 调度到不适合的节点上。如:可以防止将不需要 GPU 能力的 Pod 调度到可提供 GPU 能力的节点上;集群默认的 master 节点有node-role.kubernetes.io/control-plane:NoSchedule这样的配置,才可以避免将 Pod 调度到 master 节点等等。
一些基本的操作指令:
# 给节点node1增加一个Taint,不允许被调度
kubectl taint nodes node1 key1=value1:NoSchedule
# 删除这个Taint
kubectl taint nodes node1 key1=value1:NoSchedule-
在 Pod 中设置 Toleration,使其可以被调度到对应的节点上:
tolerations:
- key: "key1"
operator: "Equal" # operator 默认值
value: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Exists" # 此时不能指定对应的value,如无特别说明,官方指定不能的情况,加上一般会报错,无法继续进行对应的操作
effect: "NoSchedule"
- key: "" # 此时可以被调度到任何具有`NoSchedule`效果的Taint所在的节点上
operator: "Exists"
effect: "NoSchedule" # effect也可以使用其他值,如PreferNoSchedule等
- key: "key1"
effect: "" # 可以与所有key1的效果匹配
effect 允许设置的值
| value | 影响 |
|---|---|
| NoExecute | 1. 如果 Pod 不能容忍这类污点,会马上被驱逐;2. 如果 Pod 能够容忍这类污点,没有指定tolerationSeconds,则 Pod 还会一直在这个节点上运行;3. 如果 Pod 能够容忍这类污点,而且指定了tolerationSeconds,则经过这段时间之后,Pod 会逐渐被驱离这些节点 |
| NoSchedule | 除非具有匹配的容忍度,否则 Pod 不会被调度到该污点的节点,且当前正在运行的 Pod 不会被驱逐 |
| PreferNoSchedule | 偏好设置,调度器不能完全保证不会被调度到具有该污点的节点上 |
高级用法
- 可以通过自己实现一些准入控制器(AdmissionControllers)
- 可以采用一些[插件],运行
ExtendedResourceToleration准入控制器,来实现对特定设备集群的管理
基于 Taint 的驱逐
当前内置的 Taint:
node.kubernetes.io/not-readynode.kubernetes.io/unreachablenode.kubernetes.io/memory-pressurenode.kubernetes.io/disk-pressurenode.kubernetes.io/pid-pressurenode.kubernetes.io/network-unavailablenode.kubernetes.io/unschedulablenode.cloudprovider.kubernetes.io/uninitialized
DaemonSet 的特别说明
DaemonSet 控制器会自动为所有的 Pod 添加如下NoSchedule的 Toleration:
node.kubernetes.io/memory-pressurenode.kubernetes.io/disk-pressurenode.kubernetes.io/pid-pressure(v1.14+)node.kubernetes.io/unschedulable(v1.10+)node.kubernetes.io/network-unavailable(仅适用主机网络配置???)
针对以下 TaintNoExecute的 Toleration 将不会指定tolerationSeconds:
node.kubernetes.io/unreachablenode.kubernetes.io/not-ready
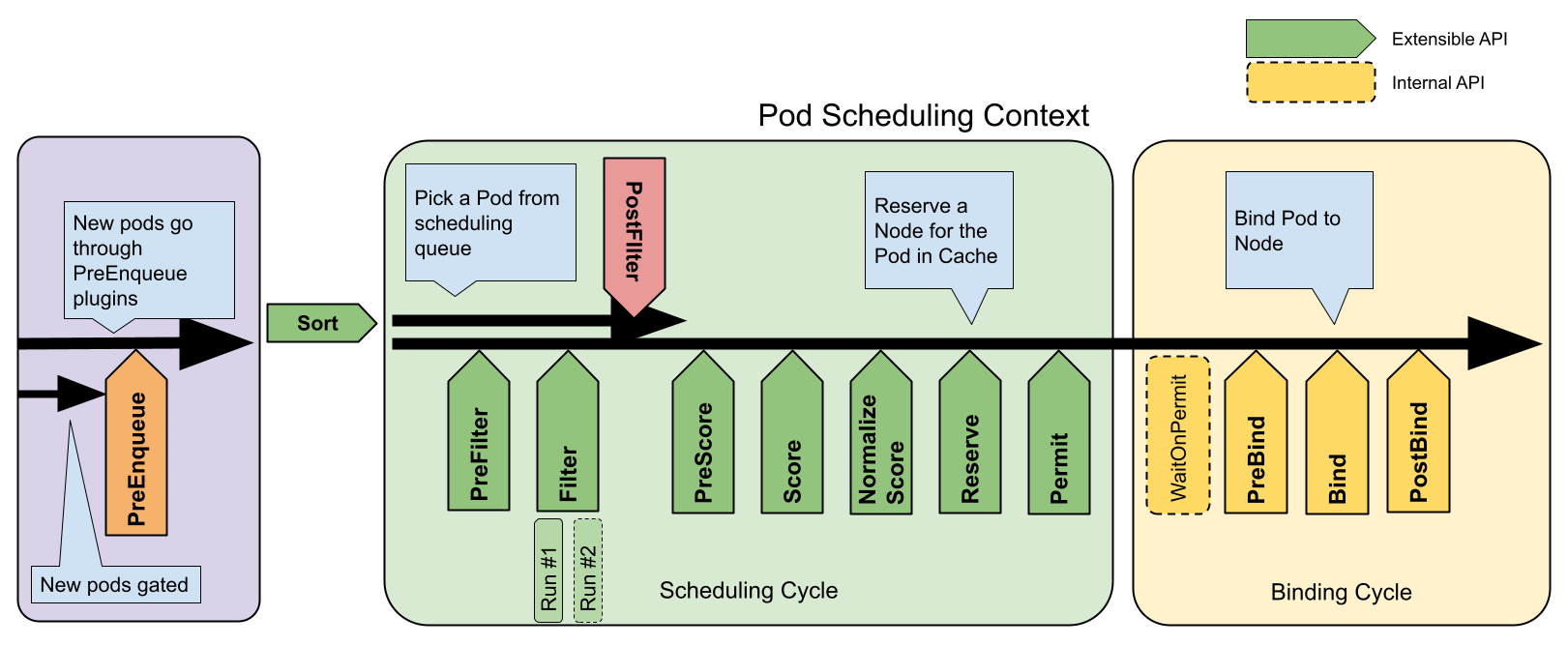
调度框架 [TBD]
动态资源分配 (alpha 特性)
feature-gate 需要被显示启用,可通过自己开发或者使用第三方插件来实现,目前(v1.29.3-)resource.k8s.io/v1alpha2API 组提供四种类型:
ResourceClass定义资源驱动程序ResourceClaim定义资源申请ResourceClaimTemplatePodSchedulingContext
调度器性能调优
对于大规模的集群(可能有 50+节点),有必要设置一个合适的percentageOfNodesToScore,让调度器快速做出响应,调度器覆盖所有节点的方式,当前的手段就是轮询遍历评估可调度性。更复杂的调度可能需要根据自己的架构特性来实现自定义调度器。
调度插件 – NodeResourcesFit
支持 2 种“bin packing”
MostAllocated基于资源的利用率来为节点计分,优选分配比率较高的节点,可以设置weight来影响调度结果RequestedToCapacityRatio允许用户基于请求值与容量的比率,针对参与节点计分的每类资源设置权重
计分函数
shape:
- utilization: 0 # 0%:节点评分为0
score: 0
- utilization: 100 # 100%:节点评分为10
score: 10
节点容量分配的评分 [TBD]
Pod 优先级与抢占
PriorityClass
PriorityClass可以允许 Pod 有优先级的区别,优先级越高的 Pod 越容易被调度,越容易进入运行状态。PriorityClass对象对应的取值范围是从 -2,147,483,648 到 1,000,000,000(含)。更大的数字用于标识集群关键 Pod 的内置PriorityClass。使用PriorityClass需要了解的点:
PriorityClass提供globalDefault(表示这个值应用于没有priorityClassName的 Pod,且系统中只能有一个设置了该字段的PriorityClass,如果不存在设置了globalDefault的PriorityClass,则没有priorityClassName的 Pod 优先级为 0)与description(任意字符串)字段。PriorityClass仅对新增的 Pod 有效,已存在的 Pod 不会因为PriorityClass的创建而提升优先级,即这类 Pod 优先级还是 0;如果删除了PriorityClass,则使用被删除的PriorityClass的 Pod 优先级保持不变,但是无法再创建已删除的PriorityClass的 Pod。
Non-preempting PriorityClass
配置了preemptingPolicy: Never的 Pod 将被放置在调度队列中较低优先级 Pod 之前,但它们不能抢占其他 Pod 的资源,等待调度的非抢占式 Pod 将留在队列中,直到有资源满足,才可以被调度。非抢占式的 Pod 如果调度失败,会以更低的频率被重试,从而允许其他较高优先级的 Pod 被调度。即无论是配置了优先级还是没有配置优先级的普通 Pod 都会被 back-off(重试)。preemptionPolicy默认为PreemptLowerPolicy,这允许这类 Pod 抢占较低优先级的 Pod(默认行为)。如果preemptionPolicy: Never,则该PriorityClass中的 Pod 将是非抢占式的。
总之,Pod 被调度的优先级顺序为:spec.priorityClassName > preemptingPolicy: Never > preemptingPolicy: PreemptLowerPriority(default,未设置也是它)
Preemption
Pod 被创建后,会进入 Pending 状态,如果没有找到足够的资源或者匹配的节点,则触发对 Pending 状态的 Pod 的抢占逻辑。也就是节点会优先部署高优先级的 Pod。同时因资源被抢占而未被调度的 Pod 会被设置nominatedNodeName字段,用于跟踪为该 Pod 保留的资源,用户可以据此判断有关集群中的抢占信息。同时被标记nominatedNodeName的 Pod 将来不一定会被部署到这个字段指定的节点,调度程序会在任何其他节点尝试,因此nominatedNodeName与nodeName并不总是相同,而且该 Pod 最终也有机会抢占另一个节点 Pod 所对应的资源。
因被抢占而被 kubelet 杀死的 Pod
会有一个体面终止期,这段时期从 Pod 被抢占开始到成功调度抢占的 Pod,因此用户可以根据实际需求适当调小低优先级 Pod 的体面终止时间,具体字段为:spec.terminationGracePeriodSeconds (default 30s),如果超过这个时间,Pod 会被 kubelet 强制杀死。
支持 PodDisruptionBudget,但不保证
PodDisruptionBudget(PDB)允许设置多副本 Pod 所有者限制因自愿性质的干扰而同时终止的 Pod 数量。调度器在抢占 Pod 时对 PDB 的支持时尽力而为的,即会尽力去寻找符合 PDB 约束的牺牲者,如果没有找到,抢占还是会进行,并且即便是违反了 PDB 约束,也会删除优先级较低的 Pod。
与低优先级 Pod 之间的亲和性 [TBT]
处于 Pending 的 Pod 与节点上的一个或多个较低优先级的 Pod 具有亲和性,如果在一个目标节点上没有除去这些具有亲和性 Pod 的其他一些低优先级 Pod,则抢占不会发生。相反,如果在另一个节点上找到合适的 Pod,也无法保证处于 Pending 的 Pod 可以被调度。
也就是说这种情况下,处于 Pending 状态的 Pod 可能永远处于 Pending,尽管它具备较高的优先级。 官方给出的解决方案是仅针对同等或更高优先级的 Pod 设置 Pod 间亲和性。
跨节点抢占
本来节点 N 上有一个处于 Pending 的 Pod P,只有当另一个节点上的 Pod Q 具有反亲和性规则,且在同一可用区,这个时候才会发生跨节点抢占,当且仅当 Pod Q 被抢占时,但是目前的版本还未实现这一点。
截止(v1.29.3)官方还没有给出跨节点抢占合理的算法,未来可能会有。
总结
抢占如果要发生,必须要满足优先级要求,即被抢占资源的永远是那些具有低优先级的 Pod。
PriorityClass 与 QoS
Pod 的优先级与 QoS,二者并无直接关联,基于 QoS 类设置的 PriorityClass 没有默认限制。QoS 类可以被用来估计 Pod 最有可能被驱逐的顺序。kubelet 根据以下因素对 Pod 的驱逐进行排名:
- 对紧俏资源的使用是否超过请求值
- Pod 优先级:如果较低优先级的 Pod 资源使用量没有超过其配额时,kubelet 不会驱逐该 Pod,相反,如果优先级较高且资源用量超过其配额时,Pod 可能被驱逐
- 相对于请求的资源使用量:当 Pod 资源使用量未超过其资源配额时,kubelet 不会驱逐该 Pod
节点压力驱逐
节点压力驱逐是 kubelet 主动终止 Pod 来释放节点资源(如 CPU,Memory,Volume,以及 fs 的 inode 等)的过程。压力驱逐期间 Pod 的状态会被 kubelet 标记为 Failed,节点压力驱逐是一个主动的过程。压力驱逐会排除设置的PodDisruptionBudget或者是 Pod 的terminationGracePeriodSeconds,对于软驱逐条件,会使用eviction-max-pod-grace-period,硬驱逐会立即杀死 Pod。
Pod 自我修复行为
- 对于受如 Deployment,RS 等控制器干预的 Pod,控制器会自动创建新 Pod 来替换旧的 Pod
- 对于创建的裸 Pod,kubelet 会尝试使用新的 Pod 来替换旧的,且这类裸 Pod 的优先级是会被 kubelet 纳入是否驱逐的因素
kubelet 的驱逐策略
- 驱逐信号:linux 系统,kubelet 使用的驱逐信号:
| eviction-signal | 描述 |
|---|---|
| memory.available | node.status.capacity[memory] - node.stats.memory.workingSet |
| nodefs.available | node.stats.fs.available |
| nodefs.inodesFree | node.stats.fs.inodesFree |
| imagefs.available | node.stats.runtime.imagefs.available |
| imagefs.inodesFree | node.stats.runtime.imagefs.inodesFree |
| pid.available | node.stats.rlimit.maxpid - node.stats.rlimit.curproc |
每个信号支持百分比或具体数值,kubelet 使用百分比来确定驱逐条件。上述具体数值的获取都是由 cgroup 提供的。
-
驱逐条件:节点上应该可用资源的最小值,格式:[eviction-signal][operator][quantity],如:memory.available < 10%,memory.available < 1G
- 硬驱逐条件,没有宽限期,立即驱逐,使用
eviction-hard如:memory.available<100Mi,nodefs.available<10% - 软驱逐条件,过了宽限期才驱逐,使用
eviction-softeviction-soft-grace-periodeviction-max-pod-grace-period如:
- 硬驱逐条件,没有宽限期,立即驱逐,使用
-
驱逐检测间隔:
housekeeping-interval(默认为 10s)评估驱逐条件
节点状态
kubelet 根据下表将驱逐信号映射为节点状态
| 节点条件 | 驱逐信号(eviction-signal) |
|---|---|
| MemoryPressure | memory.available |
| DiskPressure | nodefs.available、nodefs.inodesFree、imagefs.available 或 imagefs.inodesFree |
| PIDPressure | pid.available |
此外,control-plane-panel 还将这些节点状态映射为其 Taint。kubelet 根据配置的 –node-status-update-frequency 更新节点条件,默认为 10s。
节点状态波动
要尽量避免节点状态波动,可以设置eviction-pressure-transition-period,该值指定了不同状态必须等待的时间,默认为 5m
主动回收节点资源
- 专用 imagefs,如果有 nodefs 满足驱逐条件,kubelet 会收集死亡的 Pod 和容器;如果有 imagefs 满足驱逐条件,kubelet 将删除所有为使用的镜像
- 没有专用的 imagefs,如果节点只有一个满足驱逐条件的 nodefs,kubelet 将首先对死亡的 Pod 和容器进行垃圾回收,然后删除未使用的镜像
Pod 的驱逐顺序
如果以上的步骤,无法降低对应节点资源的压力,kubelet 将开始驱逐 Pod,根据 Pod 资源使用量与优先级等情况,按以下顺序来驱逐 Pod:
- 资源使用量超过其请求的 Pod,如
BestEffort或Burstable,会根据各自的优先级,以及资源使用超过其请求的程度被驱逐 - 资源使用量少于请求量的
Guaranteed和Burstable根据其优先级最后被驱逐
Note: QoS 不适用于
EphemeralVolume,如果节点在 DiskPressure 下,上述顺序不适用。
仅当 Guaranteed Pod 中所有容器都被指定了请求和限制并且二者相等时,才保证 Pod 不被驱逐。如果不足以缓解系统资源压力,尽管满足不被驱逐的条件,但是还是会驱逐优先级低的 Pod。
对于裸 Pod,如果希望免在资源压力下被驱逐,需要直接设置spec.priority字段,裸 Pod 不支持spec.priorityClassName。
当 kubelet 因 inode 或 进程 ID 不足而驱逐 Pod 时, 它使用 Pod 的相对优先级来确定驱逐顺序。
kubelet 根据节点是否具有专用的 imagefs 文件系统对 Pod 进行不同的排序:
- 有 imagefs,如果 nodefs 触发驱逐, kubelet 会根据 nodefs 使用情况(本地卷 + 所有容器的日志)对 Pod 进行排序。
- 没有 imagefs,如果 nodefs 触发驱逐, kubelet 会根据磁盘总用量(本地卷 + 日志和所有容器的可写层)对 Pod 进行排序。
最小驱逐回收
为 kubelet 配置--eviction-minimum-reclaim参数可免于在资源紧俏的情况下,kubelet 反复回收资源,多次驱逐
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
evictionHard:
memory.available: "500Mi"
nodefs.available: "1Gi" #达到 1Gi 的条件
imagefs.available: "100Gi" #达到 100Gi 的条件
evictionMinimumReclaim:
memory.available: "0Mi"
nodefs.available: "500Mi" #继续回收至少 500MiB,直到条件达到 1.5GiB
imagefs.available: "2Gi" #继续回收至少 2GiB,直到条件达到 102GiB
节点内存不足时的行为
如果节点在 kubelet 能够回收内存之前遇到内存不足(OOM)事件, 则节点依赖[oom_killer]来响应。
| QoS | oom_score_adj | 说明 |
|---|---|---|
| Guaranteed | -997 | 当资源非常紧俏时,最不容易被杀死 |
| BestEffort | 1000 | 仅次于 Guaranteed,有可能被杀死 |
| Burstable | min(max(2, 1000 - (1000 * memoryRequestBytes) / machineMemoryCapacityBytes), 999) | 当资源非常紧俏时,这类 Pod 最有可能被杀死 |
kubelet 还将具有 system-node-critical 优先级 的任何 Pod 中的容器 oom_score_adj 值设为 -997。如:kube-scheduler,kube-apiserver,etcd 等组件。
这意味着低 QoS Pod 中相对于其调度请求消耗内存较多的容器,将首先被杀死。
最佳实践
- 配置 kubelet 时预留一定内存给系统比如 10%,然后在加上驱逐阈值,比如 16G 的系统内存,如果驱逐阈值是 500M,则预留约 2.1G 给系统,避免系统奔溃
- 为一些节点性质的 Pod,比如 DaemonSet 控制器相关的 Pod 设置比较高的优先级,避免被 kubelet 杀死
已知问题
- kubelet 可能不会立即观察到内存压力,如果追求极端的利用率,可以使用
--kernel-memcg-notification以便在超过条件时立即执行 Pod 驱逐,如果不追求极端的利用率,可以设置--kube-reserved于--system-reserved为系统预留一定量的内存 - active_file 内存未被视为可用内存,可能导致 Pod 驱逐发生,截止(v1.29.3)这是一个已知的未解决的问题,可以通过为可能执行 I/O 密集型活动的容器设置相同的内存限制和内存请求来应对该行为,为此,将需要估计或测量该容器的最佳内存限制值
Eviction API 发起的驱逐
用户可以调用Eviction API发起驱逐,也可以通过kubectl drain发起驱逐。API 发起的驱逐遵循PodDisruptionBudget和terminationGracePeriodSeconds配置。
相关的 http 状态码
- 200:允许驱逐
- 429:Too Many Requests,当前不允许驱逐,可能因为不满足
PodDisruptionBudget配置,可稍后尝试 - 500:服务器配置错误,如多个
PodDisruptionBudget引用同一个 Pod
解决驱逐被卡住
- 暂停 Deployment 等控制器的自动化操作,可以设置如
suspend字段 - 不使用
Eviction API,直接删除对应的 Pod,如调用kubectl delete
插件: https://kubernetes.io/zh-cn/docs/concepts/configuration/manage-resources-containers/#extended-resources [oom_killer]: https://lwn.net/Articles/391222/